
本次实验代码的notebook已经上传到我的Github上,点击这里
线性预测
线性预测是一种简单的机器学习模型,它可以用来预测一个或多个输入变量与输出变量之间的关系。线性预测模型的基本形式是:
\[y = w_1x_1 + w_2x_2 + ... + w_nx_n + b\]其中 $y$ 是输出变量,$x_1, x_2, …, x_n$ 是输入变量,$w_1, w_2, …, w_n$ 是权重,$b$ 是偏置。
线性预测模型的训练过程是通过最小化损失函数来确定权重和偏置的值。损失函数的选择是非常重要的,因为它决定了模型的性能。常见的损失函数有均方误差(MSE)和平均绝对误差(MAE)。
数据集
这个实验我们使用了kaggle上常见的员工 离职数据集,HR_comma_sep.csv
数据预处理
导入数据
这里使用pandas库作为数据处理的工具,首先导入数据集,查看数据集的基本信息。
import pandas as pd
df = pd.read_csv('HR_comma_sep.csv')
print(df.head())
satisfaction_level last_evaluation number_project average_montly_hours \
0 0.38 0.53 2 157
1 0.80 0.86 5 262
2 0.11 0.88 7 272
3 0.72 0.87 5 223
4 0.37 0.52 2 159
time_spend_company Work_accident left promotion_last_5years sales \
0 3 0 1 0 sales
1 6 0 1 0 sales
2 4 0 1 0 sales
3 5 0 1 0 sales
4 3 0 1 0 sales
salary
0 low
1 medium
2 medium
3 low
4 low
可以发现,数据集中的特征有:satisfaction_level, last_evaluation, number_project, average_montly_hours, time_spend_company, Work_accident, promotion_last_5years, sales。其中sales是员工所在的部门,left是员工是否离职。
数据格式化
为了方便之后的学习过程,这里将每个column的数据单独储存。
level = df['satisfaction_level']
evaluation = df['last_evaluation']
project = df['number_project']
average_monthly_hours = df['average_montly_hours']
time_spend_company = df['time_spend_company']
work_accident = df['Work_accident']
left = df['left']
promotion = df['promotion_last_5years']
department = df['sales']
salary = df['salary']
可以发现,sales列和salary列是字符串类型的,需要将其转换为数值类型。这里使用字典映射的方式将其转换为数值类型。
department = df['sales'].map({'sales': 1, 'accounting': 2, 'hr': 3, 'technical': 4, 'support': 5, 'management': 6, 'IT': 7, 'product_mng': 8, 'marketing': 9, 'RandD': 10})
salary = df['salary'].map({'low': 1, 'medium': 2, 'high': 3})
线性模型学习
pytorch
pytorch是一个强大的开源深度学习框架,它提供了很多高效的工具和接口,可以帮助我们快速构建和训练深度学习模型。在这个实验中,我们将使用pytorch来构建和训练线性预测模型。
import torch
import torch.nn as nn
import torch.optim as optim
数据向量化
在训练模型之前,我们需要将数据向量化。这里我们将所有的特征向量化为一个矩阵,将所有的标签向量化为一个向量。
X_tensors = torch.tensor([level, evaluation, project, average_monthly_hours, time_spend_company, work_accident, promotion, department, salary], dtype=torch.float32).T
Y_tensors = torch.tensor(left, dtype=torch.float32).view(-1, 1)
其中X_tensors是特征矩阵,Y_tensors是标签向量(是否离职)。
定义模型
在pytorch中,我们可以通过继承nn.Module类来定义模型。这里我们定义了一个简单的线性预测模型。
class linear(nn.Module):
def __init__(self, input_size):
super(linear, self).__init__()
self.linear = nn.Linear(input_size, 1)
def forward(self, x):
return self.linear(x)
训练模型需要定义损失函数和优化器。pytorch有很多打包好的工具,这里我们使用均方误差(MSE)作为损失函数,使用随机梯度下降(SGD)作为优化器。
model = linear(input_size=9)
#定义损失函数
criterion = nn.MSELoss()
#定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.00001) #学习率为0.00001
注意,我们的特征矩阵有9个特征,所以输入的大小是9,即输入的input_size是9.
训练模型
torch可以方便地使用GPU进行训练(即使这个模型很简单),这里我们使用GPU进行训练。
device = torch.device('cuda')
# 将模型移动到GPU
model = model.to(device)
# 将数据移动到GPU
X_tensors = X_tensors.to(device)
y_tensor = y_tensor.to(device)
## 训练
num_epochs = 10000
losses = []
for epoch in range(num_epochs):
outputs = model(X_tensors).squeeze()
loss = criterion(outputs, y_tensor.squeeze()) #修整矩阵维度
optimizer.zero_grad()
loss.backward() # 反向传播
optimizer.step()
losses.append(loss.item())
if (epoch+1) % 1000 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
可视化
为了能够直观地看到我们的loss的变化,我们可以使用matplotlib库来绘制loss的变化曲线。
import matplotlib.pyplot as plt
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
可以看到,loss在训练过程中逐渐减小,这说明我们的模型在训练过程中逐渐收敛。
如图 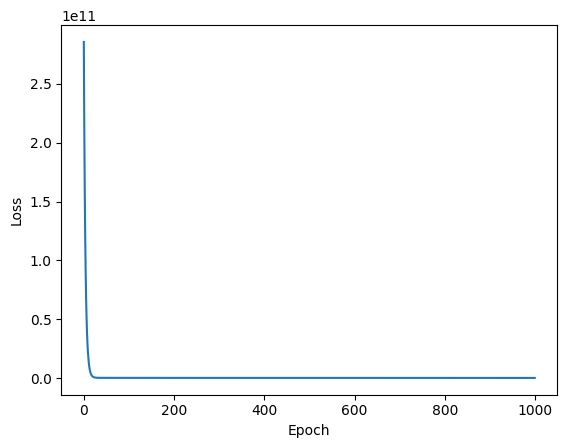
预测
训练好模型之后,我们可以使用模型来预测员工是否离 职。 注意,模型的标签要符合我们训练时标签的顺序,这里导入模型后,要把输入向量转移到GPU上。
#输入分别为 [satisfaction_level, last_evaluation, number_project, average_montly_hours, time_spend_company, Work_accident, promotion_last_5years, sales, salary]
new_house_features = torch.tensor([0.38,0.53,2,157,3,0,0,1,1]).cuda()
with torch.no_grad():
predicted_price = model(new_house_features).squeeze().item()
print("预测离职:", predicted_price)